大学入学共通テスト(数学) 過去問
令和6年度(2024年度)追・試験
問134 (情報関係基礎(第2問) 問11)
問題文
次の文章を読み、問いに答えよ。
ユウさんは、キーボードを使って手元をまったく見ることなく英単語を正確に入力する練習をしているが、誤入力が多かった。そこでユウさんは、友人のリンさんが作った、表示された単語を入力するとタイピング中の誤入力を記録してくれるソフトを使って練習を始めた(図1)。リンさんはユウさんのタイピング練習を手伝うため、ソフトが記録した結果を分析することにした。
「bug」を例にした誤入力回数の数え方は次の図2のとおりである。リンさんは図2の数え方に従って、表1と同じ手続きで、各英字について10回の練習での各位置の誤入力回数の累計を表2に記入した。また、各単語での累計誤入力回数の合計を求めて、「合計」の列に記入した。
これまでの話し合いで、「o」1個あたりの累計誤入力回数は直前にある英字の種類によって異なることがわかってきた。そこでリンさんは、「o」の直前の英字である先行英字に注目し、ユウさんはどの先行英字のときに「o」の誤入力が多いかを調べることにした。
まずリンさんは、ユウさんが各単語を再度10回ずつ練習した結果を、表2と同じ手続きで次の表4(「o」に下線を付した。)にまとめた。
次に、各先行英字を分析するため、表4をもとにして次の表5を作成した。表5には、各先行英字での「o」の累計誤入力回数の合計と誤入力割合を記入した。誤入力割合は、各先行英字に続く「o」の累計誤入力回数の合計を、その先行英字に続いて「o」が出現した回数の累計で割ったものである。例えば、先行英字「g」に「o」が続くのは、表4では「algorithm」のみで、「o」の誤入力は3回である。そのため表5において、先行英字が「g」のとき、累計誤入力回数の合計は「3」、誤入力割合は「0.3」となる。表5には「o」の誤入力が1回もなかった先行英字は掲載していない。リンさんは表4の単語の中で2回以上出現する先行英字( チ )があることに注意しながら、表5を作成した。ただし表5は作成途中のため、先行英字が「t」のときの値は記入されていない。
ここまでの結果をふまえて、リンさんは次のように考えた。
誤入力割合に注目して、「o」の誤入力割合が最も大きかった先行英字をX、次に大きかった先行英字をYとする。先行英字がXのときの誤入力割合が、Yのときの誤入力割合の2倍以上だったとき、Xに「o」が続くと間違いやすいと判断し、Xに続いて「o」が出現する単語を練習する。
リンさんが上記の考えにそって表5を調べた結果、Xには( ツ )が、Yには( テ )と( ト )がそれぞれ当てはまり、誤入力割合はXのときがYのときの2倍以上だとわかった。
「o」がどの先行英字に続くときに間違いやすいかを特定することができたリンさんは、次回練習する単語の候補のうち、特に誤入力が多くなりそうな単語「( ナ )」を表示するように、ソフトを設定した。
( ス )、( セ )にあてはまるものを1つ選べ。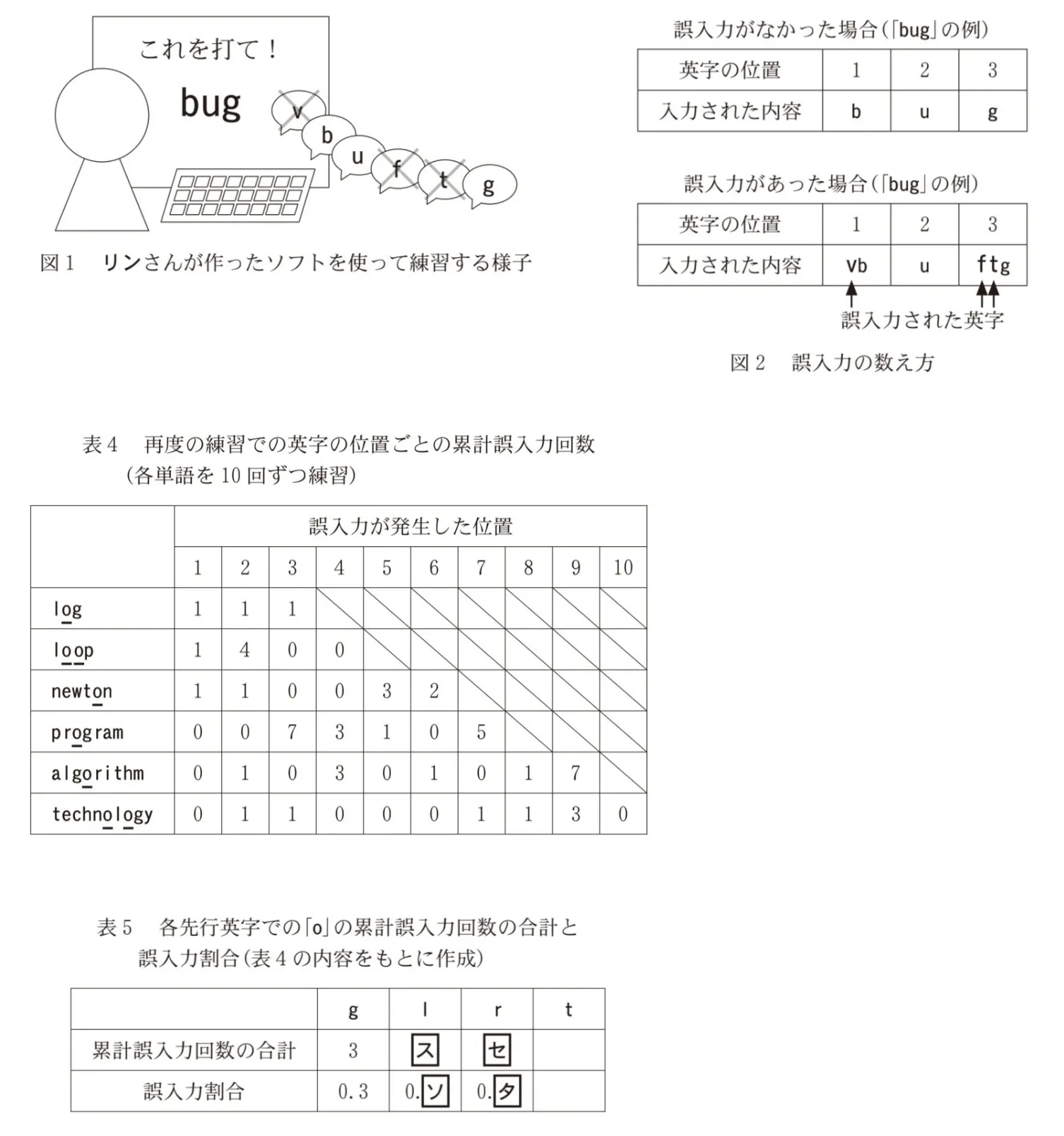
ユウさんは、キーボードを使って手元をまったく見ることなく英単語を正確に入力する練習をしているが、誤入力が多かった。そこでユウさんは、友人のリンさんが作った、表示された単語を入力するとタイピング中の誤入力を記録してくれるソフトを使って練習を始めた(図1)。リンさんはユウさんのタイピング練習を手伝うため、ソフトが記録した結果を分析することにした。
「bug」を例にした誤入力回数の数え方は次の図2のとおりである。リンさんは図2の数え方に従って、表1と同じ手続きで、各英字について10回の練習での各位置の誤入力回数の累計を表2に記入した。また、各単語での累計誤入力回数の合計を求めて、「合計」の列に記入した。
これまでの話し合いで、「o」1個あたりの累計誤入力回数は直前にある英字の種類によって異なることがわかってきた。そこでリンさんは、「o」の直前の英字である先行英字に注目し、ユウさんはどの先行英字のときに「o」の誤入力が多いかを調べることにした。
まずリンさんは、ユウさんが各単語を再度10回ずつ練習した結果を、表2と同じ手続きで次の表4(「o」に下線を付した。)にまとめた。
次に、各先行英字を分析するため、表4をもとにして次の表5を作成した。表5には、各先行英字での「o」の累計誤入力回数の合計と誤入力割合を記入した。誤入力割合は、各先行英字に続く「o」の累計誤入力回数の合計を、その先行英字に続いて「o」が出現した回数の累計で割ったものである。例えば、先行英字「g」に「o」が続くのは、表4では「algorithm」のみで、「o」の誤入力は3回である。そのため表5において、先行英字が「g」のとき、累計誤入力回数の合計は「3」、誤入力割合は「0.3」となる。表5には「o」の誤入力が1回もなかった先行英字は掲載していない。リンさんは表4の単語の中で2回以上出現する先行英字( チ )があることに注意しながら、表5を作成した。ただし表5は作成途中のため、先行英字が「t」のときの値は記入されていない。
ここまでの結果をふまえて、リンさんは次のように考えた。
誤入力割合に注目して、「o」の誤入力割合が最も大きかった先行英字をX、次に大きかった先行英字をYとする。先行英字がXのときの誤入力割合が、Yのときの誤入力割合の2倍以上だったとき、Xに「o」が続くと間違いやすいと判断し、Xに続いて「o」が出現する単語を練習する。
リンさんが上記の考えにそって表5を調べた結果、Xには( ツ )が、Yには( テ )と( ト )がそれぞれ当てはまり、誤入力割合はXのときがYのときの2倍以上だとわかった。
「o」がどの先行英字に続くときに間違いやすいかを特定することができたリンさんは、次回練習する単語の候補のうち、特に誤入力が多くなりそうな単語「( ナ )」を表示するように、ソフトを設定した。
( ス )、( セ )にあてはまるものを1つ選べ。
このページは閲覧用ページです。
履歴を残すには、 「新しく出題する(ここをクリック)」 をご利用ください。
問題
大学入学共通テスト(数学)試験 令和6年度(2024年度)追・試験 問134(情報関係基礎(第2問) 問11) (訂正依頼・報告はこちら)
次の文章を読み、問いに答えよ。
ユウさんは、キーボードを使って手元をまったく見ることなく英単語を正確に入力する練習をしているが、誤入力が多かった。そこでユウさんは、友人のリンさんが作った、表示された単語を入力するとタイピング中の誤入力を記録してくれるソフトを使って練習を始めた(図1)。リンさんはユウさんのタイピング練習を手伝うため、ソフトが記録した結果を分析することにした。
「bug」を例にした誤入力回数の数え方は次の図2のとおりである。リンさんは図2の数え方に従って、表1と同じ手続きで、各英字について10回の練習での各位置の誤入力回数の累計を表2に記入した。また、各単語での累計誤入力回数の合計を求めて、「合計」の列に記入した。
これまでの話し合いで、「o」1個あたりの累計誤入力回数は直前にある英字の種類によって異なることがわかってきた。そこでリンさんは、「o」の直前の英字である先行英字に注目し、ユウさんはどの先行英字のときに「o」の誤入力が多いかを調べることにした。
まずリンさんは、ユウさんが各単語を再度10回ずつ練習した結果を、表2と同じ手続きで次の表4(「o」に下線を付した。)にまとめた。
次に、各先行英字を分析するため、表4をもとにして次の表5を作成した。表5には、各先行英字での「o」の累計誤入力回数の合計と誤入力割合を記入した。誤入力割合は、各先行英字に続く「o」の累計誤入力回数の合計を、その先行英字に続いて「o」が出現した回数の累計で割ったものである。例えば、先行英字「g」に「o」が続くのは、表4では「algorithm」のみで、「o」の誤入力は3回である。そのため表5において、先行英字が「g」のとき、累計誤入力回数の合計は「3」、誤入力割合は「0.3」となる。表5には「o」の誤入力が1回もなかった先行英字は掲載していない。リンさんは表4の単語の中で2回以上出現する先行英字( チ )があることに注意しながら、表5を作成した。ただし表5は作成途中のため、先行英字が「t」のときの値は記入されていない。
ここまでの結果をふまえて、リンさんは次のように考えた。
誤入力割合に注目して、「o」の誤入力割合が最も大きかった先行英字をX、次に大きかった先行英字をYとする。先行英字がXのときの誤入力割合が、Yのときの誤入力割合の2倍以上だったとき、Xに「o」が続くと間違いやすいと判断し、Xに続いて「o」が出現する単語を練習する。
リンさんが上記の考えにそって表5を調べた結果、Xには( ツ )が、Yには( テ )と( ト )がそれぞれ当てはまり、誤入力割合はXのときがYのときの2倍以上だとわかった。
「o」がどの先行英字に続くときに間違いやすいかを特定することができたリンさんは、次回練習する単語の候補のうち、特に誤入力が多くなりそうな単語「( ナ )」を表示するように、ソフトを設定した。
( ス )、( セ )にあてはまるものを1つ選べ。
ユウさんは、キーボードを使って手元をまったく見ることなく英単語を正確に入力する練習をしているが、誤入力が多かった。そこでユウさんは、友人のリンさんが作った、表示された単語を入力するとタイピング中の誤入力を記録してくれるソフトを使って練習を始めた(図1)。リンさんはユウさんのタイピング練習を手伝うため、ソフトが記録した結果を分析することにした。
「bug」を例にした誤入力回数の数え方は次の図2のとおりである。リンさんは図2の数え方に従って、表1と同じ手続きで、各英字について10回の練習での各位置の誤入力回数の累計を表2に記入した。また、各単語での累計誤入力回数の合計を求めて、「合計」の列に記入した。
これまでの話し合いで、「o」1個あたりの累計誤入力回数は直前にある英字の種類によって異なることがわかってきた。そこでリンさんは、「o」の直前の英字である先行英字に注目し、ユウさんはどの先行英字のときに「o」の誤入力が多いかを調べることにした。
まずリンさんは、ユウさんが各単語を再度10回ずつ練習した結果を、表2と同じ手続きで次の表4(「o」に下線を付した。)にまとめた。
次に、各先行英字を分析するため、表4をもとにして次の表5を作成した。表5には、各先行英字での「o」の累計誤入力回数の合計と誤入力割合を記入した。誤入力割合は、各先行英字に続く「o」の累計誤入力回数の合計を、その先行英字に続いて「o」が出現した回数の累計で割ったものである。例えば、先行英字「g」に「o」が続くのは、表4では「algorithm」のみで、「o」の誤入力は3回である。そのため表5において、先行英字が「g」のとき、累計誤入力回数の合計は「3」、誤入力割合は「0.3」となる。表5には「o」の誤入力が1回もなかった先行英字は掲載していない。リンさんは表4の単語の中で2回以上出現する先行英字( チ )があることに注意しながら、表5を作成した。ただし表5は作成途中のため、先行英字が「t」のときの値は記入されていない。
ここまでの結果をふまえて、リンさんは次のように考えた。
誤入力割合に注目して、「o」の誤入力割合が最も大きかった先行英字をX、次に大きかった先行英字をYとする。先行英字がXのときの誤入力割合が、Yのときの誤入力割合の2倍以上だったとき、Xに「o」が続くと間違いやすいと判断し、Xに続いて「o」が出現する単語を練習する。
リンさんが上記の考えにそって表5を調べた結果、Xには( ツ )が、Yには( テ )と( ト )がそれぞれ当てはまり、誤入力割合はXのときがYのときの2倍以上だとわかった。
「o」がどの先行英字に続くときに間違いやすいかを特定することができたリンさんは、次回練習する単語の候補のうち、特に誤入力が多くなりそうな単語「( ナ )」を表示するように、ソフトを設定した。
( ス )、( セ )にあてはまるものを1つ選べ。
- ス:2 セ:3
- ス:3 セ:4
- ス:4 セ:5
- ス:5 セ:6
- ス:6 セ:7
- ス:7 セ:7
正解!素晴らしいです
残念...
この過去問の解説
前の問題(問133)へ
令和6年度(2024年度)追・試験 問題一覧
次の問題(問135)へ